Navigator Metadata Server Management
The Navigator Metadata Server is one of the two roles that provides Cloudera Navigator data management functionality. The Navigator Metadata Server manages, indexes, and stores entity metadata extracted from cluster services. Using policies defined by data stewards and others, the Navigator Metadata Server can tag entities with metadata or take other actions during the extraction process. It is the metadata that enables data discovery and data lineage functions for Cloudera Navigator.
This section starts with an overview of the Navigator Metadata Server system architecture and then covers administrator tasks that require Cloudera Manager Admin Console such as adding the Navigator Metadata Server role to an existing cluster, tuning for optimal performance, and setting up the LDAP or Active Directory groups to use Cloudera Navigator role-based access privileges.
Navigator Metadata Architecture
The figure below shows a high-level view of the key components that make up the Cloudera Navigator Metadata Architecture. Extracting, indexing, and storing metadata from cluster entities, both on-premises and in the cloud, are some of the important processes implemented by this architecture. As shown in the figure below, Cloudera Navigator can also extract metadata from entities stored on cloud services (Amazon S3) and from clusters running on Amazon EC2 or Cloudera Altus.
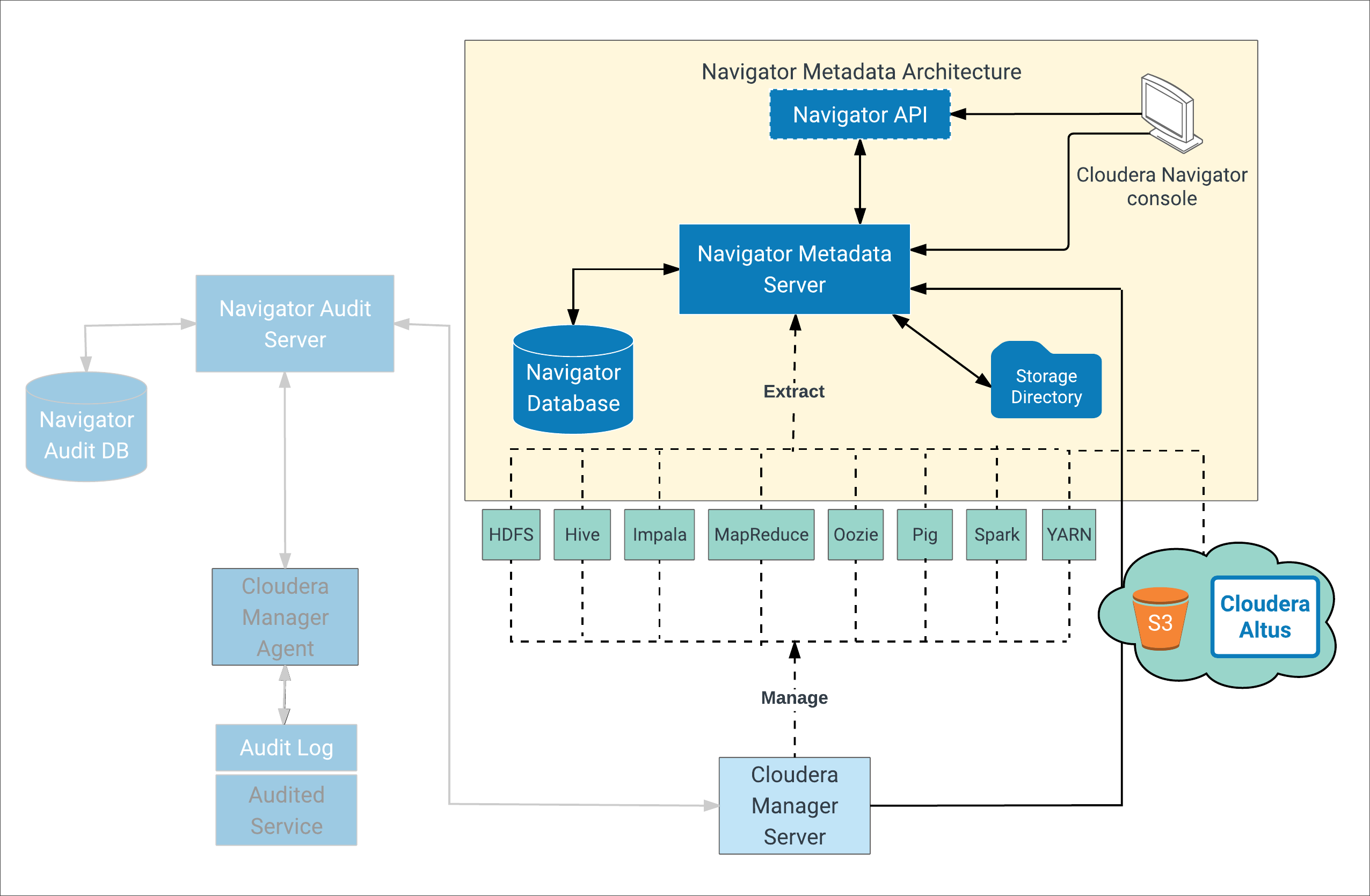
 Note: Not all services are shown in the image above (for example, Sqoop1).
Note: Not all services are shown in the image above (for example, Sqoop1).For example, a policy may specify that all Hive table entities with table name budget_2017 be tagged with the managed metadata property name finance-team, or that any entities with a file creation date (technical metadata) prior to 2014 be labeled with the prefix archive-yyyy, with the specific year obtained from the file creation date and applied to the label.
Extracted metadata is then indexed for later search using the embedded Solr instance. Solr Documents that comprise the index are stored on disk in the storage directory at the location configured in Cloudera Manager Admin Console for the Navigator Metadata Server datadir. See Metadata Architecture In More Detail for more detail.
- Manages authorization data for Cloudera Navigator users
- Manages audit report metadata
- Generates metadata and audit analytics
- Exposes the Cloudera Navigator APIs
- Hosts the web server that provides the Cloudera Navigator console. (The web server and the console are also used to support the Cloudera Navigator Auditing services.)
The Navigator Database stores policies, user authorization and audit report metadata, and analytic data. Extracted metadata and the state of extractor processes is kept in the storage directory.
Metadata Architecture In More Detail
| Resource Type | Metadata Extracted |
|---|---|
| HDFS | HDFS metadata at the next scheduled extraction run after an HDFS checkpoint. If the cluster is configured for high availability (HA), metadata is extracted at the same time it is written to the JournalNodes. |
| Hive | Database, table, and query metadata from Hive lineage logs. See Managing Hive and Impala Lineage Properties. Hive entities include tables that result from Impala queries and Sqoop jobs. |
| Impala | Database, table, and query metadata from the Impala Daemon lineage logs. See Managing Hive and Impala Lineage Properties. |
| MapReduce | Job metadata from the JobTracker. The default setting in Cloudera Manager retains a maximum of five jobs; if you run more than five jobs between Navigator extractions, the Navigator Metadata Server extracts the five most recent jobs. |
| Oozie | Oozie workflows from the Oozie Server. |
| Pig | Pig script runs from the JobTracker or Job History Server. |
| S3 | Bucket and object metadata. |
| Spark | Spark job metadata from YARN logs. |
| Sqoop 1 | Database and table metadata from Hive lineage logs; job runs from the JobTracker or Job History Server. |
| YARN | Job metadata from the ResourceManager. |
An entity created at system time t0 is extracted and linked by Cloudera Navigator after the 10-minute extraction poll period and the appropriate service-specific interval, as follows:
- HDFS: t0 + (extraction poll period) + (HDFS checkpoint interval (1 hour by default))
- HDFS + HA: t0 + (extraction poll period)
- Hive: t0 + (extraction poll period) + (Hive maximum wait time (60 minutes by default)
- Impala: t0 + (extraction poll period)
Metadata Indexing
After metadata is extracted, it is indexed and made available for searching by the embedded Solr engine. The Solr instance indexes entity properties and the relations among entities. Relationship metadata is implicitly visible in lineage diagrams and explicitly available by downloading the lineage using the Cloudera Navigator APIs.
Data stewards and other business users explore entities of interest using the Cloudera Navigator console. Metadata and lineage that has been extracted, linked, and indexed can be found using Search. See Lineage, Metadata and other sections in this guide for Cloudera Navigator console usage information. The following sections focus on using the Cloudera Manager Admin Console for systems management tasks.
Continue reading:
| << Publishing Audit Events | ©2016 Cloudera, Inc. All rights reserved | Setting Up Navigator Metadata Server >> |
| Terms and Conditions Privacy Policy |