Troubleshooting Navigator Data Management
This page contains troubleshooting tips and workarounds for various issues that can arise.
Continue reading:
Navigator Audit Server
"No serializer found" error
Symptom: Selecting an Audits page results in error message.
No serializer found
Possible cause: Communication failure somewhere between Navigator Metadata Server and Cloudera Manager Server and its communication to Navigator Audit Server. This is an existing Known Issue that needs to be resolved so that the error message can be properly mapped.
- Log in to the Cloudera Navigator console.
- Enable Navigator API logging.
- Perform your action on the Audits page that raised the error message and see if the underlying issue is caught in the API log. If the Navigator API logging reveals no additional
information, turn on API logging for Cloudera Manager:
- Log in to the Cloudera Manager Admin Console.
- Select
- Select Advanced for the Category filter.
- Click the Enable Debugging of API check box to select it. The server log will contain all API calls. Try your request again and see if the source error message displays in the response.
Processing a backlog of audit logs
Problem: You have logs that include audit events that were not processed by the Cloudera Navigator Audit Server, such as logs for events that took place before audit server was online or during a period when audit server was offline.
Solution: A backlog of logs can be processed by audit server as follows:
- Determine what days were not processed and will need to have partitions created for them. The audit log files have the UNIX epoch appended to their name:
hdfs-NAMENODE-341ad9b94435839ce45b8b22e7c805b3-HdfsAuditLogger-1499844328581
You want the dates from the oldest and newest files. You can do this by sorting the list and identifying the first and last files. For example, for HDFS audit files:
The oldest: $ ls ./hdfs* | head -1
The newest: $ ls ./hdfs* | tail -1
Depending on your shell, you can convert the epoch value to a date using date -r epoch.
- Create partitions in the Navigator Audit Server database for days that have missing audits.
Create a partition from an existing template table using SQL commands. Use SHOW TABLES to list the template tables. For example, the template table for HDFS is HDFS_AUDIT_EVENTS.
Using MySQL as an example, if you have partitions up to March 31, 2017 and your audit logs include HDFS data for the first week of April, you would run the following SQL commands:
CREATE TABLE HDFS_AUDIT_EVENTS__2017_04_01 LIKE HDFS_AUDIT_EVENTS; CREATE TABLE HDFS_AUDIT_EVENTS__2017_04_02 LIKE HDFS_AUDIT_EVENTS; CREATE TABLE HDFS_AUDIT_EVENTS__2017_04_03 LIKE HDFS_AUDIT_EVENTS; CREATE TABLE HDFS_AUDIT_EVENTS__2017_04_04 LIKE HDFS_AUDIT_EVENTS; CREATE TABLE HDFS_AUDIT_EVENTS__2017_04_05 LIKE HDFS_AUDIT_EVENTS; CREATE TABLE HDFS_AUDIT_EVENTS__2017_04_06 LIKE HDFS_AUDIT_EVENTS; CREATE TABLE HDFS_AUDIT_EVENTS__2017_04_07 LIKE HDFS_AUDIT_EVENTS;
- Change the Navigator Audit expiration period to be longer than the time period of the logs you want to process.
Set the expiration period in Cloudera Manager. Search for the property “Navigator Audit Server Data Expiration Period”.
- Stop the Cloudera Manager agent on the host running the role for the service whose logs will be restored.
For example, if the logs are for HDFS, stop the agent on the namenode. For HiveServer2, stop the Cloudera Manager agent on the node where HiveServer2 is running. See Starting, Stopping, and Restarting Cloudera Manager Agents.
If you aren’t sure of which host is involved, the log files contain the UUID of the role which generated them. Go to the host defined for that role. For high-availability clusters, make sure that you stop the role on the active host.
- On that host, copy the backed up audit logs to the audit directory.
The location is typically /var/log/service/audit. For example, /var/log/hadoop-hdfs/audit. The specific locations are configured in the Cloudera Manager audit_event_log_dir properties for each service.
- Move the WAL file out of this directory. (Back it up in a safe location.)
- Restart the Cloudera Manager agent.
On restart, Cloudera Manager agent will not find the WAL file and will create a new one. It will process the older audit logs one by one.
- Verify that the audits appear in Navigator.
You can also check the contents of the WAL file to see which logs were processed.
Navigator Metadata Server
"Missing required field: id" (Solr exception)
Symptom: After removing the Navigator Metadata Server storage directory (the datadir), an error message for the id field displays.
[qtp1676605578-63]: org.apache.solr.common.SolrException: [doc=0002ac6b75cb17721ad8324700f473cb] missing required field: id
Possible cause: This error indicates that the Navigator Metadata Server database and storage directory are out-of-sync because of a change that was made in the Cloudera Navigator 2.9 (Cloudera Manager 5.10) release. When the Navigator Metadata Server role starts, it compares state information in the database with the same information in the storage directory. This error can appear if the storage directory has been deleted but the database has not.
Steps to resolve: If this error message occurs and the storage directory was recently deleted, you can remove the stale state information from the database. To do this:
- Take note of the Navigator Metadata Server Storage Dir directory.
Log into Cloudera Manager and browse to . Note the storage directory location.
- Stop the Navigator Metadata Server role by navigating to .
- Log in to the database instance configured for use with Navigator Metadata Server.
- Run the following SQL commands:
delete from NAV_UPGRADE_ORDINAL; insert into nav_upgrade_ordinal values (-1, -1);
- Start Navigator Metadata Server role using .
The Navigator Metadata Server role should restart successfully.
Repairing metadata in the storage directory after upgrading
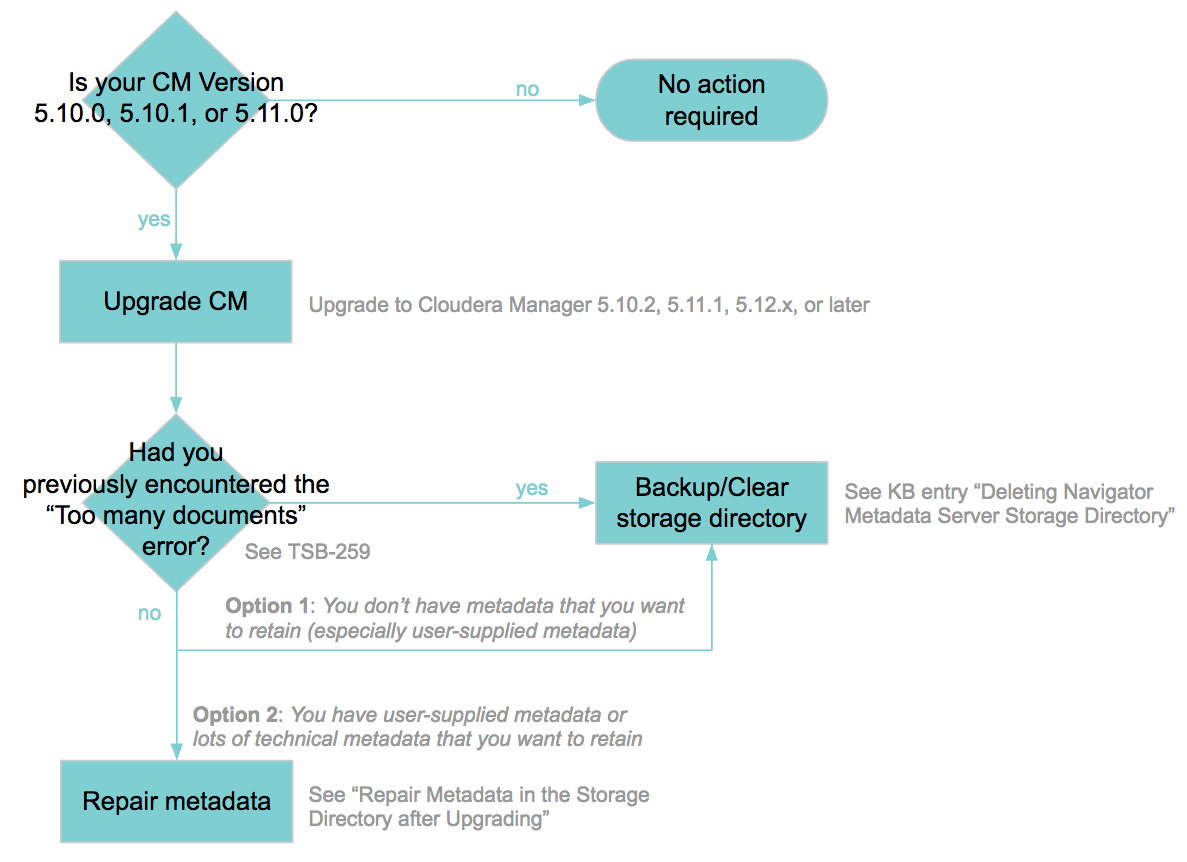
If you ran Cloudera Navigator on Cloudera Manager versions 5.10.0, 5.10.1, or 5.11.0, you should upgrade to a later release immediately to avoid a known software problem as reported in the knowledge base entry "Upgrade needed for Cloudera Navigator included with Cloudera Manager releases 5.10.0, 5.10.1, and 5.11.0 due to high risk of failure through exhausting data directory resources." This document describes some additional steps to perform after upgrade to mitigate for duplicate and potentially broken relation metadata added to the Navigator storage directory because of the broken versions.
To fully recover the Navigator storage directory:
- Upgrade Cloudera Manager to 5.10.2, 5.11.1, or later releases.
- Set properties to enable background repair tasks.
From Cloudera Manager, go to .
Enter the following configurations to the "Navigator Metadata Server Advanced Configuration Snippet (Safety Valve) for cloudera-navigator.properties" property.
nav.backend.task.TRIGGER_HIVE_TABLES_EXTRACTION.enabled=true nav.backend.task.HDFS_PC_RELATIONS_BUILDER.enabled=true nav.backend.task.HDFS_MR_RELATIONS_BUILDER.enabled=true nav.backend.task.PIG_HDFS_RELATIONS_BUILDER.enabled=true
- Restart the Navigator Metadata Server role.
The full cycle of cleaning up the relations may take days or weeks depending on the number of relations affected.
These instructions correspond to “Repair metadata” in the following decision tree:
| << User Roles and Privileges Reference | ©2016 Cloudera, Inc. All rights reserved | Cloudera Operation >> |
| Terms and Conditions Privacy Policy |